Research objectives
The main objective of our research is to understand which learning mechanisms can enable autonomous agents (biological or artificial) to show behavioral flexibility and adaptation capabilities in their partially unknown and changing environment.
The long-term fundamental objective is to come up with a unified theory of the brain mechanisms that permit mammals to adapt to a variety of different situations. In terms of applications, this could lead us to a new generation of robots that do not need to be re-conceived or re-tuned for each specific task encountered.
Approach
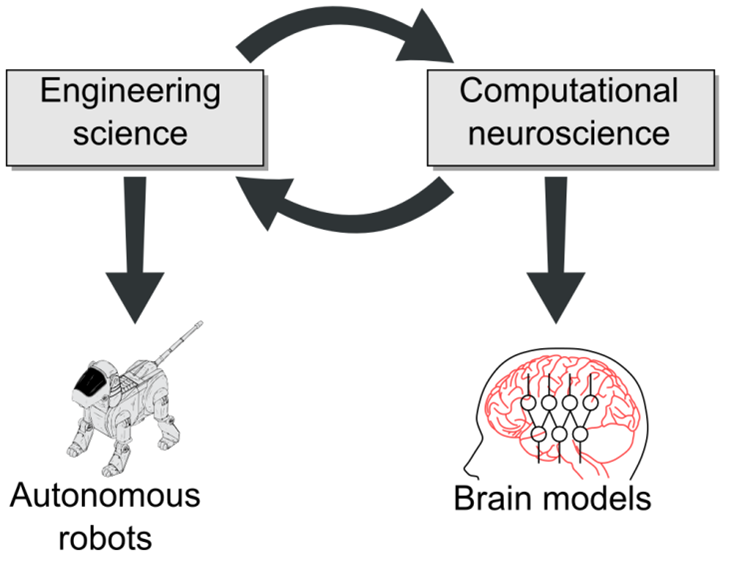
Our research strategy follows an interdisciplinarity approach where 1) the design of models for computational neuroscience enables us to better understand brain learning mechanisms and to design novel biological experiments to test our theories; 2) the transfer of these models to cognitive robotics enables us to improve robots’ behavioral flexibility and to conceive robots that interact more naturally with humans; 3) robotic tests of neuro-inspired models enable us to improve these models and thus to generate novel predictions for biology (Fig. 1).
Summary of research accomplishments
Following this approach, we have proposed novel models of brain learning and decision-making mechanisms in mammals (humans, non-human primates, rodents) in a variety of experimental paradigms : navigation, instrumental conditioning, Pavlovian conditioning, and repeated probabilistic games involving a monetary reward. We found that sometimes the same learning mechanisms were appropriate for these different contexts (Khamassi and Humphries 2012, Lesaint et al. 2014b, Genzel et al. 2019). We raised novel experimental predictions (e.g., Humphries et al. (2012), Lesaint et al. (2015)) that could later be verified through collaborations with experimentalists (e.g., Lee et al. (2018), Cinotti et al. (2019)). Our model-based analyses of behavior and brain activity contributed to a better neurophysiological characterization of learning processes in brain areas such as the prefrontal cortex, basal ganglia, hippocampus and the dopaminergic system. Moreover, several of our findings showed cases where we could refute alternative models (e.g., Khamassi et al. (2015), Bavard et al. (2018), Cinotti et al. (2019)).
Insights from this work has also allowed us to improve learning abilities of a variety of robots (humanoids, wheeled robots) in similar scenarios : navigation, sequence learning, probabilistic learning, non-stationary problems, social interaction. We built robots that can autonomously explore their environment and learn a cognitive map for efficient navigation, and quick adaptation to changes in goal location (Caluwaerts et al. 2012). We systematically showed that the performance of our learning algorithms was either better or similar to standard engineering methods (Renaudo et al. 2015b, Khamassi et al. 2018, Velentzas et al. 2018) while at the same time reducing computation cost (Chatila et al. 2018). We moreover showed that the same models for the coordination of several parallel learning processes were efficient between different scenarios, such as navigation, sequential visuo-motor control and social interaction (e.g., Renaudo et al. (2015a), Khamassi et al. (2016), Chatila et al. (2018)), thus avoiding specific re-tuning by the human between scenarios. Finally, to our knowledge we designed the first humanoid robot which can learn online (on-the-fly) during social interactions with typical children as well as children with autism (Zaraki et al. 2019).
A few examples of past research are depicted below.
Cognitive bio-inspired humanoid robotics
A neuromimetic model was developped to describe neural mechanisms in the prefrontal cortex for decision-making and reinforcement learning. The model mimicks the way the prefrontal cortex uses reward information to update values associated to different possible actions, and to regulate exploration during decision-making (i.e. sometimes exploiting learned action values, and sometimes exploring by choosing suboptimal actions so as to gather new information).
Here the model is applied to a simple human-robot game. The robot has to find under which cube a star (reward) is hidden. The robot alternates between exploration (searching for the correct cube) and exploitation phases (repeating the same choice). In addition, the model mimicks the way the prefrontal cortex monitores performance and can associate some cues or task events to variations in performance. This enables the robot to learn by itself to recognize that some objects or events are associated with changes in the task and thus shall be followed by a re-exploration.
Work done in collaboration with Peter Ford Dominey (INSERM U846, Lyon), Emmanuel Procyk (INSERM U846, Lyon), Stéphane Lallée (INSERM U846, Lyon) and Pierre Enel (INSERM U846, Lyon).
Related publications:
- Khamassi, M. and Lallée, S. and Enel, P. and Procyk, E. and Dominey, P.F. (2011). Robot cognitive control with a neurophysiologically inspired reinforcement learning model.
Frontiers in Neurorobotics. Vol 5:1 Pages 1-14. - Khamassi, M. and Wilson, C. and Rothé, R. and Quilodran, R. and Dominey, P.F. and Procyk, E. (2011). Meta-learning, cognitive control, and physiological interactions between medial and lateral prefrontal cortex.
Mars, R.B., Sallet, J., Rushworth, M.B. and Yeung, N. (Eds) Neural Basis of Motivational and Cognitive Control, Cambridge, MA: MIT Press, publisher. Pages 351-370. - Khamassi, M. and Enel, P. and Dominey P.F. and Procyk, E. (2013). Medial prefrontal cortex and the adaptive regulation of reinforcement learning parameters.
Progress in Brain Research. Vol 202 Pages 441-464. Pammi, V.S.C. and Srinivasan, N. (Eds.) Decision Making: Neural and Behavioral Approaches. - Khamassi, M. and Quilodran, R. and Enel, P. and Dominey P.F. and Procyk, E. (2015). Behavioral regulation and the modulation of information coding in the prefrontal cortex. Cerebral Cortex, 25(9):3197-218.
Neuromimetic models of action selection and spatial navigation
This work aimed at proposing a computational model for the coordination of navigation strategies in rodents and their associated learning mechanisms. The model was funded on experimental evidence showing that mammals are able to alternate between strategies relying on a mental (« cognitive ») map of the environment and cue-guided or response strategies. In particular, depending on the current uncertainty, stability and familiarity of the environment, rats are able to choose the most appropriate strategy for a given task.
The proposed computational model comprised a new formal hypothesis for the interaction between brain systems during navigation (Dollé et al., 2008; 2010; 2018). A hippocampal module containing « place cells » projected to prefrontal cortical cortical columns representing nodes of a topological map of the environment. Planning within this map resulted in suggested paths which were sent to a striatal module selecting movements according to the planning strategy. This module was in competition with two other striatal modules: one for a cue-guided learning through reinforcement to associate visual cues with directions of movements; one for an exploration strategy proposing random movements. Finally, a specific cortico-striatal modules called the « gating network » was dedicated to the selection of the strategy which should guide behavior at which moment. This gating network learns with reinforcement learning which strategy is the most efficient in each context. The model was used in simulation to reproduce a series of existing rat behavioral data in navigation mazes.
The second part of the work consisted in testing the robustness of the model on a robotic platform with noisy and unpredictable interactions with the real-world (Caluwaerts et al., 2012a,b). During exploration, the Psikharpax robot builds a mental (« cognitive ») map of the environment by observing the configuration of visual cues and integrating odometry measurements. After exploration, the robot can reach any goal location. Efficient trajectories emerge out of the coordination of 2 behavioral strategies :
(1) planning (using the map)
(2) taxon (cue-guided).
Related publications:
- Dollé, L. and Khamassi, M. and Girard, B. and Guillot, A. and Chavarriaga, R. (2008). Analyzing interactions between navigation strategies using a computational model of action selection.
Spatial Cognition VI. Learning, Reasoning, and Talking about Space, Springer, publisher. Pages 71-86. - Dollé, L. and Sheynikhovich,D. and Girard,B. and Chavarriaga,R. and Guillot,A. (2010). Path planning versus cue responding: a bioinspired model of switching between navigation strategies.
Biological Cybernetics. Vol 103 No 4 Pages 299-317. - Caluwaerts, K. and Staffa, M. and N’Guyen, S. and Grand, C. and Dollé, L. and Favre-Felix, A. and Girard, B. and Khamassi, M. (2012). A biologically inspired meta-control navigation system for the Psikharpax rat robot.
Bioinspiration & Biomimetics. Vol 7(2):025009 Pages 1-29. - Caluwaerts, K. and Favre-Felix, A. and Staffa, M. and N’Guyen, S. and Grand, C. and Girard, B. and Khamassi, M. (2012). Neuro-inspired navigation strategies shifting for robots: Integration of a multiple landmark taxon strategy. Living Machines 2012, Lecture Notes in Artificial Intelligence, Prescott, T.J. et al. (Eds.). Vol 7375/2012 Pages 62-73. Barcelona, Spain.
- Dollé, L. and Chavarriaga, R. and Guillot, A.* and Khamassi, M.* (2018). Interactions of spatial strategies producing generalization gradient and blocking: a computational approach.
PLoS Computational Biology. Vol 14 No 4 Pages e1006092 (* equally contributing authors).
Reinforcement Learning and Meta-Learning
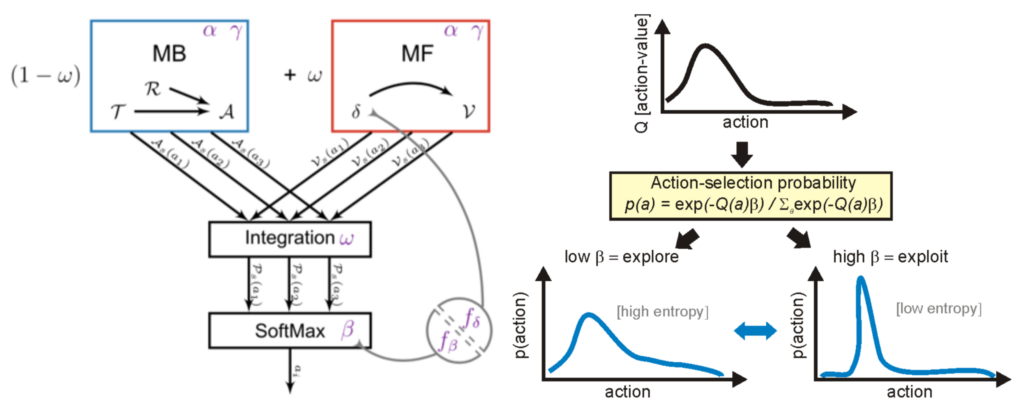
Our research group has been involved in a series of theoretical studies aiming at proposing novel computational models for the coordination of learning processes in the brain (e.g., Dollé et al. (2018)). In particular, we have proposed that animals’ behavioral flexibility in a wide range of tasks can be partially explained by their ability to alternate between two forms of reward-based learning : model-based (MB) and model-free (MF) reinforcement learning (RL). The former is the case where the animal attempts to learn an internal model of the task structure (e.g., a cognitive map in the case of navigation), and uses this model to mentally plan sequences of actions to the goal. The latter is the case where the agent learns local action values in order to make fast reactive decisions (Fig. 2).
Through the years, we have used these models to predict activity of different brain areas such as the prefrontal cortex, basal ganglia, the hippocampus and the dopaminergic system. The latter is known to emit dopamine, a neuromodulator associated with the feeling of pleasure and resulting in learning through potentiation of synaptic plasticity in target areas (Robbins and Everitt 1992). Importantly, the standard theory posits that dopamine neurons’ activity encodes a reward prediction error (RPE) signal : it increases in response to unexpected rewards, it decreases when an expected reward is omitted, it remains silent when things are as predicted (Schultz et al. 1997). This RPE signal is similar to the reinforcement signal generated by model-free algorithms such as temporal-difference learning, developed in the field of Machine Learning (Sutton and Barto 1998).
Nevertheless, two key puzzling experimental results remained in contradiction with this theory and unexplained. Experiments in humans showed that dopamine is not always involved in learning, but sometimes affects only performance (Shiner et al. 2012). In rats, it has moreover been shown that different individuals have different learning strategies and that only some show a dopamine-dependent learning process. Importantly, neurophysiological recordings showed that an RPE signal could be found only in individuals whose learning is dopamine-dependent (Flagel et al. 2011).
Using a neurophysiologically detailed neural network model of the basal ganglia, we raised the novel hypothesis that dopamine should not only affect learning, but also the exploration-exploitation (E-E) trade-off : high dopamine levels should focus decisions on the action with the highest value ; low dopamine levels should promote exploration of actions with low values (Humphries et al. 2012) (Fig. 2). Our model simulations moreover predicted that some behavioral effects usually interpreted in terms of learning should actually be the result of this E-E trade-off. The next section will present experimental validation of this prediction.
We then incorporated this E-E trade-off within our MB-MF coordination model, and showed that it could explain dopamine-independent learning processes in subjects with a high contribution of MB to decisions, and dopamine-dependent learning in subjects with a high MF contribution (Lesaint et al. 2014). We moreover used the model to derive novel predictions, namely that changing the duration between events of the task (i.e., decreasing the inter-trial interval) should leave less time for animals to experience negative RPEs, which should thus favor the contribution of the MF system to their decisions and should restore a RPE-like dopamine pattern of activity in their brain (Lesaint et al. 2015). The next section will present experimental validation of this prediction.
Related publications:
- Humphries, M. and Khamassi, M. and Gurney, K. (2012). Dopaminergic control of the exploration-exploitation trade-off via the basal ganglia.
Frontiers in Neuroscience. Vol 6:9 Pages 1-14. - Lesaint, F. and Sigaud, O. and Flagel, S.B. and Robinson, T.E. and Khamassi, M. (2014). Modelling individual differences observed in Pavlovian autoshaping in rats using a dual learning systems approach and factored representations. PLoS Computational Biology, 10(2): e1003466.
- Lesaint, F. and Sigaud, O. and Clark, J.J. and Flagel, S.B. and Khamassi, M. (2015). Experimental predictions drawn from a computational model of sign-trackers and goal-trackers.
Journal of Physiology – Paris. Vol 109 No 1-3 Pages 78-86. - Dollé, L. and Chavarriaga, R. and Guillot, A.* and Khamassi, M.* (2018). Interactions of spatial strategies producing generalization gradient and blocking: a computational approach.
PLoS Computational Biology. Vol 14 No 4 Pages e1006092 (* equally contributing authors).
Neurophysiology of the prefrontal cortex, striatum and dopaminergic neuromodulation in mammals
Since I have been trained to perform neurophysiological recordings in behaving rats during my PhD thesis, a number of neurophysiologists have been kind enough to confidently share their data with our group, and to even sometimes co-design novel experimental protocols in order to test some of our model predictions.
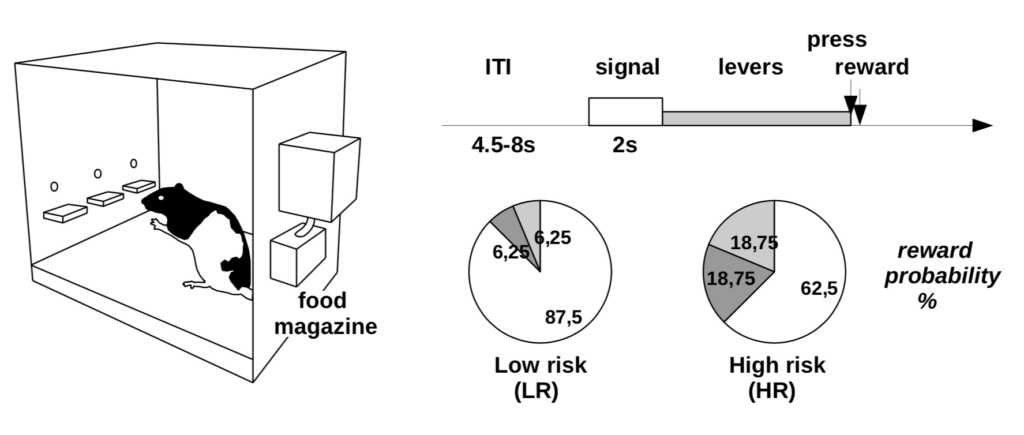
One example of such collaboration occurred during an ANR project (Learning Under Uncertainty, 2012-2015) where I have led a work-package on model-based analysis of brain and behavioral data. With neurophysiologists at the CNRS in Bordeaux, we designed a new task in rats involving learning between three levers associated with different reward probabilities (Fig. 3). This task was meant to test our prediction that dopamine affects the exploration-exploitation trade-off during learning (Humphries et al. 2012). We designed the task like a non-stationary probabilistic three-armed bandit task, so that rats constantly needed to relearn which was the best lever. We were able to verify this prediction by showing that dopamine blockade impairs exploration but not learning once the rats had been habituated to the task (Cinotti et al. 2019).
During the same ANR project, we have collaborated with an INSERM group in Lyon to show that the prefrontal cortex guides alternations between exploration and exploitation phases in monkeys. We fitted different computational models to the data, and performed model comparison in order to refute alternative models. We moreover showed that prefrontal cortex activity was correlated with model variables determining switches between exploration and exploitation (Khamassi et al. 2015).
During an ANR-NSF collaboration grant, we have co-designed a novel protocol to test another model prediction with an experimental group at the NIH in Baltimore, USA. We verified the prediction that changing the inter-trial interval would change dopamine activity, and showed that dopamine RPE patterns do not only depend on individual differences but also on the history of interaction with the environment (Lee et al. 2018).
Related publications:
- Bellot, J. and Sigaud, O. and Khamassi, M. (2012). Which Temporal Difference Learning algorithm best reproduces dopamine activity in a multi-choice task?.
From Animals to Animats: Proceedings of the Twelfth International Conference on Adaptive Behaviour (SAB 2012), Ziemke, T., Balkenius, C., Hallam, J. (Eds), Springer, publisher. Vol 7426/2012 Pages 289-298. Odense, Denmark. BEST PAPER AWARD. - Bellot, J. and Sigaud, O. and Roesch, M. R. and Schoenbaum, G. and Girard, B and Khamassi, M. (2012). Dopamine neurons activity in a multi-choice task: reward prediction error or value function?
Proceedings of the French Computational Neuroscience NeuroComp/KEOpS’12 workshop. Pages 1-7. Bordeaux, France. - Khamassi, M. and Humphries, M. D. (2012). Integrating cortico-limbic-basal ganglia architectures for learning model-based and model-free navigation strategies.
Frontiers in Behavioral Neuroscience, 6:79. - Humphries, M. and Khamassi, M. and Gurney, K. (2012). Dopaminergic control of the exploration-exploitation trade-off via the basal ganglia.
Frontiers in Neuroscience. Vol 6:9 Pages 1-14. - Khamassi, M. and Quilodran, R. and Enel, P. and Dominey P.F. and Procyk, E. (2015). Behavioral regulation and the modulation of information coding in the prefrontal cortex. Cerebral Cortex, 25(9):3197-218.
- Lee, B. and Gentry, R. and Bissonette, G.B. and Herman, R.J. and Mallon, J.J. and Bryden, D.W. and Calu, D.J. and Schoenbaum, G. and Coutureau, E. and Marchand, A. and Khamassi, M. and Roesch, M.R. (2018). Manipulating the revision of reward value during the intertrial interval increases sign tracking and dopamine releases.
PLoS Biology. Vol 16 No 9 Pages e2004015. - Cinotti, F.* and Fresno, V.* and Aklil, N. and Coutureau, E. and Girard, B. and Marchand, A.° and Khamassi, M.° (2019). Dopamine blockade impairs the exploration-exploitation trade-off in rats.
Scientific Reports. Vol 9 Pages 6770 (* equally contributing authors) (° equally contributing senior authors).
